Computer-assisted data extraction from the
taxonomical literature
Jim Diederich*, Renaud Fortuner**, and Jack Milton*
*Department of Mathematics, University of California, Davis, CA 95616,
USA
dieder@math.ucdavis.edu
milton@math.ucdavis.edu
**11, place de la Frézellière, 86420 Monts sur Guesnes, France. Correspondant du Muséum National d'Histoire Naturelle, Paris, France. fortuner@wanadoo.fr
Key words: biological character data, computer-assisted data extraction, published data, identification, biology, nematodes
Jim Diederich
This paper may be cited if a proper reference is given:
Diederich, J., Fortuner, R. & Milton, J. (1999). Computer-assisted data
extraction from the taxonomical literature. Virtual publication on web
site: http://math.ucdavis.edu/~milton/genisys.html.
Abstract
This article presents some problems associated with the acquisition of
morphological data from printed descriptions of taxa and our solution to
these problems.
An electronic tool, the Terminator, was used in 1993 for testing our approach.
After an article has been scanned into electronic form and run through
OCR processing, the Terminator aids the operator to identify all the characters
present in the description, record them in a standard format, and store
them prior to the creation of a database. Some difficulties one can expect
in the creation and the population of such a database are discussed. The
prototype has been implemented primarily for use with descriptions of plant-parasitic
nematodes. The complexity of our set of characters, which necessitated
new concepts to handle the set, has required changes to the tools originally
built to create and manage the set. When this task is completed, the Terminator
will have to be modified accordingly, and it will be reformulated into
a generic tool, as we see no inherent reasons that it cannot be adapted
for other biological domains.
Introduction
We have previously (Diederich et al., 1997a) proposed a representation
of morpho-anatomical characters based on a decomposition of traditional
systematic characters into: i) a biological structure (taken in a hierarchy
from the whole organism to systems, organs, tissues, cells, cell organites,
and molecules); ii) the aspects of this structure that is being described
(taken from a list of about 20 basic properties, see Diederich, 1997);
iii) and the state or value taken by the basic property in a particular
species or individual.
Once a character set has been created for a particular biological group
using this representation, it can be used to create a morpho-anatomical
database that will house the descriptions of taxa (species, genera, families,
etc.) in this group. The question remains as to how to populate this database.
This article proposes a possible approach that has been prototyped and
tested with a set of nematode descriptions.
Creating a character database
New data vs. published data
The first question to be answered is whether we should create a character
database from new data gathered for this purpose or rely on published data.
The first option would solve many problems such as those presented by missing
data and format ambiguities. However, this would not be possible for taxonomic
groups of more than a few species. Recording new data for, e.g., the 8,000
populations of plant-parasitic nematodes that have been described over
the last hundred years would require, first, to conduct a worldwide sampling
expedition, then to extract and process 8,000 samples (actually much more
because it would take more than one sample to find each targeted population),
then to record the data, to the tune of more than one day per sample. This
is just not an option for practicing nematologists.
The alternative is to use published data. Existing published data are far
from perfect, but they exist. While problems raised by missing data and
differences in format are unavoidable, a great amount of published data
has been recorded by some of the best (i.e., reliable) past or still active
taxonomists. We cannot be certain that our new data would be more accurate.
Some of the data from the literature is probably better than anything a
systematic worldwide survey would provide, depending on the expertise of
the surveyors.
The creation of a general database with published data is the only practical
option, but the question remains as to how to do it . This can be done
by hand with the operator reading the data directly from the printed documents
and entering it in the proper place in existing forms, or data extraction
and entry can be assisted by computer, using several possible methods discussed
below.
This article describes the approach we propose for the creation of such
a database, as well as some difficulties we can expect to encounter during
this task. The task remains daunting, but we have designed electronic tools
to help in this endeavor. While ours is by no means an automated system,
it makes the task at least possible.
The tools were prototyped a few years ago during the NEMISYS project (Nematode
Identification System), but they are of a sufficiently general nature that
we see no major problems in extrapolating them to other biological domains.
We have therefore begun the GENISYS Project (General Identification System),
which makes the construction of similar databases in other areas closer
at hand.
Possible approaches to published data acquisition
There are two basic methods that can be used to acquire the data: manual
data entry, and electronic data entry via a scanner and optical character
recognition (OCR) processing. With the second option, one has three options:
(i) store only the text without trying to extract and store character data
in a database, (ii) use natural language processing to aid placement of
the data in the database, or (iii) use some other means short of natural
language processing.
Manual data entry
Manual entry can be cost effective if the amount of data to be entered
is reasonably small. Even if the amount is substantial it can be entered
manually if it can be done in a very systematic way by entering data for
the same few characters repeatedly. Furthermore, if the data is simple,
the errors can probably be kept to a minimum, though one cannot escape
the tedium of the continual typing. Another advantage of manual entry is
that it eliminates the need for any pre processing such as scanning, but
the saving would not be great, as most of pre-processing can be done by
data-entry personnel.
Unfortunately, these conditions are rarely met in biological descriptions.
The descriptions, outside of a few basic measurements, are not written
in any systematic fashion and so one must often jump from one character
to a much different character to enter the data. A typical nematode description
contains about 50 to 80 characters out of a list of over 5,000 characters
that currently exist in our system. A few characters are found in all descriptions,
but others were used only by one or a few authors. The data are complex,
often involving measurements, thus making it likely there will be entry
mistakes. With a vast literature the list of known characters is not stable,
and more characters must be added to it with each processed description,
particularly early in the task. The general morphological database we are
proposing to construct will be so large that manual data entry would likely
be made, not by a taxonomist but by a data entry operator, i.e., someone
who would be unfamiliar with the domain and who would not be able to make
expert judgments about biological data. However, some character names may
not be easy to find in the published descriptions, and only experts may
be able to decide exactly what character is being described. This would
make it impossible to entrust to a data entry operator who is not a taxonomist
the task of extracting the characters directly from a printed description.
The creation of a general data matrix (i.e., one that includes all possible
characters for all existing species in a large group) is an almost impossible
task using manual entry, which probably explains why nobody has ever succeeded
in such an endeavor.
Scanning published descriptions
Using the method of electronic scanning and OCR processing presumes
a large amount of data, enough to warrant the investment in a scanner and
OCR software, although the costs are quite low. This initial part of the
process can be done by persons without any scientific training, if they
are given explicit scanning instructions. OCR processing will introduce
errors into the text, either spelling errors or scanning errors in measurements,
such as substituting the letter l or o for the digits one or zero, or missing
or adding decimals, but there are ways for handling such problems. The
time required to scan, process OCR, and spell-check is quite reasonable,
as discussed below. It should be noted that an ever increasing amount of
taxonomic descriptions are already available in an electronic form from
the author or the publisher, which will simplify the process for such new
data.
After the text of the description has been transferred to an electronic
medium, the three electronic options for data extraction listed above are
available, and the choice depends to some extent on the intended use of
the data.
Full text storage
The first option (simply storing and retrieving the electronic text)
only requires correcting errors introduced by the OCR. Spelling errors
can be corrected through a word processor, and this requires only that
a list of terms from the application domain have been entered in the user
defined dictionary. Correcting the numerical errors could be tedious without
some preprocessing software with a good interface to help make the corrections.
The corrected text could then be retrieved by keyword methods (Salton,
1989), or in the future by text-based intelligent systems (Jacobs, 1992)
when they have been significanlty developed. However, for uses of the data
for such purposes as identification this would be of limited value and
would be very inefficient unless the user had already guessed the probable
identity of the organism and needs only to check the description of the
corresponding species. The user would still have to retrieve all of the
articles containing a description of the candidate species and then locate
the descriptions in each article. For many uses the data are required in
a structured form, for example for similarity comparisons, and full text
would insufficient for such a tasks.
It would be much more difficult to retrieve descriptions with specific
values for particular characters. For this kind of search, keyword methods
in themselves do not work very well without some kind of enhancement. Some
data is extremely cryptic, and it is unlikely that searching the descriptions
would find the desired data. For example, published descriptions of nematode
species often include abbreviations. For example, in nematology, the traditional
character Ratio a (the ratio of length to width of Body) often is
represented simply by the letter a. It is unlikely that text retrieval
systems could differentiate between the article a and the ratio
a and find the latter in descriptions. Also, distributing the copies
of a published article raises copyright concerns. Copyright protection
for data is a hotly debated topic (Samuelson, 1992; 1996).
Natural language processing
The second option is to use some natural language processing (NLP Ð
see Special Issue on NLP, 1996) to help place the characters in a database.
NLP has moved in this direction in recent years due to the hugh quantities
of available on-line text which needs to be processed to be useful as there
is too much information available to be read in detail. This work is done
under the rubric of Information Extraction (IE) (Cowie & Lehnert, 1996)
and the general thrust of this work is to summarize text for the intended
audience such as news reports and financial reports and transactions (Jacobs,
1992).
The preparation of the text after scanning would be the same as in the
first option, though it could be assumed that the spell checker would rely
on the terms already entered in the lexicon prepared for NLP. However,
the time and expertise required to create a lexicon and knowledge base
for the terms in a domain would be considerable, the lexicon would have
to be updated as new articles were processed, and new terms would have
to be added. Though NLP can do well in restricted domains, it is unclear
how well they could do in handling biological descriptions. The output
would have to be checked carefully by a domain expert, since reading articles
requires a lot of expert judgment. New lexicons would have to be built
for each additional biological domain or for processing descriptions in
other languages. It is unclear what later savings in time would result
from building a lexicon. We are unaware of any inexpensive systems that
could be used for NLP, and it is unclear that the necessary enhancements
to such a system, discussed below, would be included if such a package
becomes available.
Use of a schema
The last option is based on the schema, i.e., a formal list of morphologicalcharacters and related information organized for use in a database system. This schema originates from the character set created according to the principles and guidelines set by Diederich (1997) and Diederich et al. (1997a). The schema is used as the launching point for acquiring the data itself. The schema, as we have defined it in the previous two references, contains great deal of the word combinations one expects to find in the descriptions, a significant part of the form information takes in the sciences (Harris et al, 1989).
This approach requires the text of the descriptions to be transferred
to an electronic medium, but the terms for the spell checker would be available
from the schema and many of the problems with handling OCR errors with
measurements can be finessed. Given that a lexicon is not constructed,
the system would have to be keyword based. This makes the transition from
one biological domain to another or from one language to another easier
than with NLP systems. While basic keyword systems may need some enhancements
to give reasonable performance, the developers of NLP systems readily admit
"they are fast, portable, relatively inexpensive, and relatively easy
to learn" while "By contrast, natural language processing can
be slow brittle, and expensive" (Jacobs, 1992). Also,it is crucial
that the interface is well designed to make alternative actions quick and
efficient when the keyword approach fails. It is this option that we describe
in this paper, and we feel that it is a reasonable balance between options
one and two. Perhaps the main point here is that a well constructed list
of characters and a good interface provide a solid foundation for data
aquisition requiring otherwise fairly simple concepts for processing.
The Terminator: a tool for semi-automated data extraction
The Terminator, so named because it is based on key words, or terms,
is a set of tools for (i) reading electronic versions of descriptions and
aiding with the decomposition of characters and the placement of the data
in records, (ii) reading tables of data after having been rearranged in
a simpler format, (iii) reviewing, changing, and recovering the data, and
(iv) storing the data in a form that can be used to import the data into
a commercial DBMS. In conjunction with these activities, a schema tool
assists in the creation and management of the schema. The schema creation
and management functions are of critical importance, as without a good
schema the data would be nearly useless: fraught with redundancy, lacking
uniform structure and meaning, and containing information that cannot easily
be found and used. At this point neither a biological database management
system nor a biological knowledge base management system is commercially
available to support the complex relationships among biological characters
needed in a large identification system. However, we have taken an important
step in this direction by building the prototype of a schema tool to manage
large sets of characters.
Prototypes of the Terminator and the schema tool were built in the early
90's and used for testing our approach in 1993 (see below). However, full
size tools have not been prepared, not because of any intrinsic problem
with our concepts, but because the size of our schema is so large and the
difficulties so fundamental that we have spent the time since then working
on concepts and practical considerations to solve these (Diederich, 1997;
Diederich et al., 1997a; 1997b).
Extracting data from the printed literature using the Terminator includes
several main steps: (i) retrieving the appropriate articles from the literature,
(ii) scanning them electronically using commercial optical character recognition
(OCR) software, (iii) spell-checking, (iv) dividing the text into blocks
(normally one block consists of the description of one population), and
(v) running the Terminator tools to extract the data either from text or
from tables. The domain expert identifies the appropriate articles, and
then steps i, ii, and iii can be done by operators with very little knowledge
of the domain. Steps iv and v should be done by a trained domain expert,
at least in the present state of the prototype.
The Terminator Interface, Processing text
Basic Actions
Since interface design is a critical element in creating a usable and
efficient system, it is important to give some idea of how the Terminator
operates. Indeed, throughout the development of the Terminator prototype,
interface considerations proved to be a very important driving element
of the overall design of the system (Diederich & Milton, 1993). User
interactions also help to illustrate additional information which must
be captured in the course of processing species descriptions. What is described
here provides the essential elements of a specification of the system.
It must be noted that the description below is based on the 1993 prototype,
as no current version of the tool exists. The future version of Teminator
will integrate new concepts defined since 1993 and its operating principles
and interface will be somewhat different but the 1993 prototype gives a
good illustration of the principles and philosophy we put into the tool.
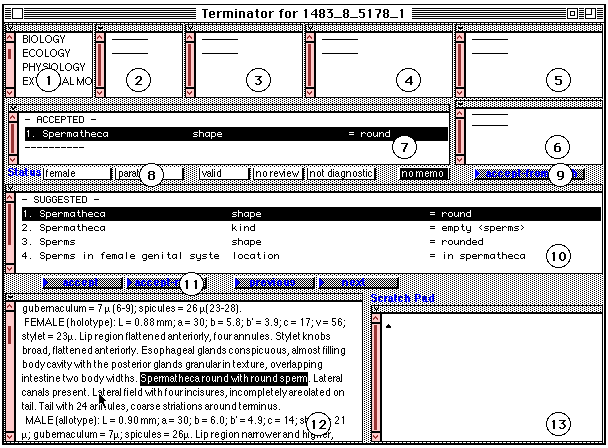
Figure 1 shows the window for the Terminator.
The scanned text appears in pane 12. To begin to process this text, the
operator clicks the mouse with the cursor on the button labeled Next
in the collection of buttons numbered 11. The Terminator proceeds through
the text in chunks (roughly sentences or phrases separated by punctuation
within a sentence), as this or other buttons are repeatedly pushed. The
chunk highlighted in pane 12 reads spermatheca round with round sperms.
Following suggested interpretation by the Terminator, a list of the suggested
candidate characters appears in pane 10. The best candidate character (Spermatheca,
shape, round) has been highlighted by the system. It happens to be
the correct character in this example. Once a candidate character is highlighted,
pushing the Accept button 11 causes it to appear in pane 7 as an
accepted character. The operator can also proceed to the next chunk by
pushing the Accept/next button which both accepts the current choice
and moves to consider the next chunk. During description processing, a
majority of the operations performed by the operator involve the accept/next
button alone.
If a chunk is related to more than one character the Terminator usually
comes up with suggestions for all characters, and they are displayed in
the list in pane 10. The operator can accept as many as are appropriate.
There is no limitation, and several records can be created from a single
chunk.
Alternative Actions
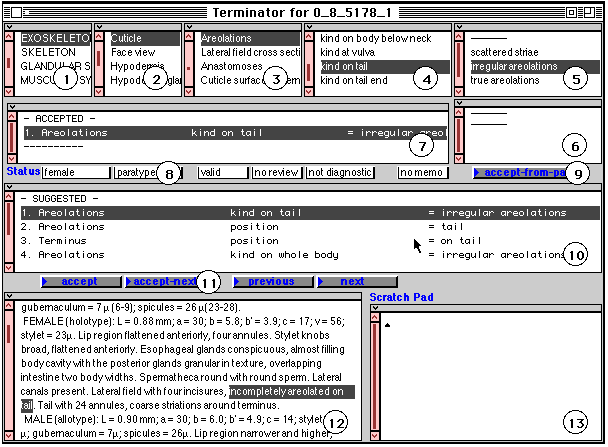
Sometimes the Terminator will not find the correct character at all.
For example, during the processing of the chunk incompletely areolated
on tail (Figure 2), the system was
unable to find the correct character. However, two of the candidates, Areolations/kind
on tail/irregular areolations and Areolations/kind on whole body/irregular
areolations, do include the correct structure, Areolations.
If item 1 in pane 10 is selected, a menu item for that pane called Get
path causes a path through the hierarchy to be highlighted in panes
1 through 5: Exoskeleton, to which Areolations belongs, is highlighted
in pane 1; the main structure, Cuticle, is highlighted in pane 2; the Areolations
itself is highlighted in pane 3; and the list of corresponding properties
appears in pane 4. The operator can scroll the list of those properties,
select the correct one (kind on tail in this case), and finally
select the correct state (irregular areolations in this case)
from pane 5.
Sometimes the characters appearing in pane 10 are too far from the mark
and do not even include the correct structure name. In this case the operator
can highlight a word in the chunk, e.g., part of a structure, and use the
Find command. The system finds all places where this word appears
in the schema and produces a list. When the operator selects one of the
characters in the list, it is displayed in panes 1 through 5 and it can
be accepted as previously. If all else fails the operator has the option
of scrolling and selecting the correct biological system in pane 1, structure
in pane 2, substructure in pane 3, property in pane 4, and state in pane
5 or value in pane 6. This happens very infrequently.
Pane 6 is used to handle numerical values found within a chunk when problems
arise, e.g., when there has been a scanning error. The operator uses pane
6 to enter a new set of values or modify an existing one.
The biological structure, basic property, and state/value panes have some
menu items that assist in understanding the schema, such as definitions
or synonyms for the biological structures and basic properties in
the schema. The status panes (panes 8 in Figure 1) are used to record important
information about the data, such as the stage being described (female,
male, juvenile, cyst, etc.), the type of specimens (holotype, paratypes,
syntype, etc., or non-type material), the errors, if any, in
the original description (not valid), the difficult characters that
the operator wants to be checked by the expert (review), the diagnostic
characters, and general remarks made by the operator. Qualifiers that are
found in the text (sometimes, usually, often, rarely, etc.) can
also be entered.
The Terminator Interface, Processing tables
Some articles contain data in tables. Tables cannot be processed in
the same way as text, because (i) the chunks are not free-flowing and are
not delimited by commas, which requires a different approach to processing,
(ii) in a scanned document converted to ASCII the rows and columns often
do not line up, which makes them difficult to read, (iii) sometimes different
columns represent different populations that must be kept separate, (iv)
character names and other information in the headers often are more cryptic
than in written text, which requires additional interpretation, and (v)
there are many different formats for tables, with headers as different
populations, different species, or characters, although characters are
the row headers in most tables.
We resolved some of these problems during the scanning stage and others
with modifications to the Terminator prototype, although tables are handled
in the current version of Terminator by doing more manual work than would
be ideal. For example, delimiters are entered manually to indicate the
beginning of each header and character. Also, all of the various formats
found in the literature are reduced manually during pre-processing to the
single format that is most commonly found (columns = populations; rows
= characters). This means that, at the expense of some manual processing,
the current Terminator can be used to extract data from tables. The Terminator
must accommodate the fact that each column refers to a different population
or a different species, but at least the rows are most often characters.
Description Processing by the Terminator
In this section we discuss how the Terminator determines the list of
characters to propose in the Suggested pane in the window (pane
10 of Figure 1). Again, this is based on the protptype version of 1993
and the operating principles of a future updated version may be somewhat
different.
When the text is first processed, the system attempts to determine where
the true periods are that mark the end of sentences, as opposed to periods
that appear in measurements, in abbreviations, or as stray marks misinterpreted
by the OCR as periods. Once a sentence is identified it is decomposed into
chunks, phrases that are separated by commas and semicolons. Some errors
in measurements can be automatically corrected, whereby l's and o's (ells
and ohs) can be converted to 1's and 0's (ones and zeros).
The system uses what is primarily a keyword approach. The keywords are
those that appear in the hierarchical schema of structures along with their
properties and states. However, the schema does not have to have a hierarchy
of structures and substructures to work. A flat schema would work as well.
Common words such as articles and prepositions can easily be eliminated
from the list of keywords by creating a fairly small list of common words
to be excluded.
Our approach does not rely on exact word matching, nor does it require
that roots of words be specified. For example, the words annulus, annuli,
annule, annulated, and annules are all sufficiently close that
it is not necessary to specify or determine whether annul is a root.
Terms that do not match closely enough can be put into a global list of
synonymous terms for explicit matching. Also, synonyms are allowed in the
schema, so many synonyms are automatically handled in the hints, as discussed
below. It is useful for a few variations in spelling, such as oesophagus
vs. esophagus, to have a global list of synonyms so that they do
not need to be listed as synonymous everywhere in the schema where one
or the other appears.
Keyword matching alone does not work particularly well. Generally, proposed
enhancements to keyword-based systems include means for weighing and ranking
the selected candidates and statistical methods for associating terms in
a dictionary. We have found that we get reasonable performance using keywords
with just some simple heuristics.
One of the main features used in the system is a set of hints, which are
automatically generated by the system after the schema is created. (While
the hints comprise the main elements used by the system, other information
in the schema plays a role, such as whether the property is quantitative
or qualitative so that quantitative properties are not considered if measurements
are not found in the sentence.) A hint has the form [word, pattern, schema-element].
For example, ['tail', ('tail' 'end' 'mucro'), <structure element>]
is one hint for the word tail when it is encountered in a sentence.
The pattern consists of the words comprising the name or a synonym of the
name of the schema-element, e.g. ('tail' 'end' 'mucro') in this example.
The <structure element> is a structure, property of a structure,
or state of a property of a structure that is specific to this hint. Likewise
['tail', ('tail' 'end' 'annuli'), <structure element>] is also a
hint for the word tail.
For each sentence, the system attempts to determine which biological structures
are possible candidates before treating individual chunks. This is done
by first selecting those structure hints whose first entry, i.e., the word,
matches sufficiently well with some word in the sentence. Some of the hints
selected are then discarded if their patterns fail to match other words
in the sentence sufficiently well. For example, the sentence: The end
of the tail is rounded generates several hints, including the two hints
in the example above, because words in the sentence match two of the three
words in their pattern. In this particular case, however, the two resulting
<structure element>s would be rejected due to other criteria discussed
below. No other words in this example hint at other structures. For example,
the word rounded does not match any structure names, but it does
match several state names, and it will be used at a later stage when chunks
are processed. The surviving hints for the structure elements are used
to form a hierarchy of nodes for the sentence. The nodes of the hierarchy
represent structures and substructures of those elements well matched with
the words in the sentence. The system then proceeds with the analysis of
each chunk of the sentence.
Each chunk within the sentence inherits a copy of the hierarchy of nodes
for the sentence. Then, the system selects hints for properties and states
that match words within the chunk sufficiently well. If the corresponding
properties and states are associated with structures already in the hierarchy
of nodes for the sentence, they are added as nodes below their respective
structures. The other hints are discarded, unless they belong to substructures
of other structures in the hierarchy. For example, for the chunk Lip
region rounded, ... the original hierarchy of nodes includes a node
for the structure Lip region. In the schema, the property state
rounded is associated with a structure named Outline that
is not in the original hierarchy of nodes because it does not appear in
the sentence. However, Outline is a substructure of the structure
Lip region, which is a node in the hierarchy. Consequently, the
hint associated with the state rounded is used to add a node for
Outline to the hierarchy for the given chunk.
A number of simple strategies are used to compensate for the system's lack
of linguistic knowledge. The example in the previous paragraph shows how
the system deals with implicit references. Another strategy is to designate
some words as must words. For instance, in the examples of hints
previously given, the words mucro and annuli are designated
as structure words that must appear in the sentence for the hint
to be added to the hierarchy of nodes for the sentence or a chunk of the
sentence. It is easy for the domain expert to establish a list of structure
names that are must words, that is, words that one expects to see in most
situations when the corresponding structure is discussed. Must words are
also given for character states. For example, in lemon- shaped,
the word lemon is a must word, while shape is not. The net
effect is to eliminate hints like ['tail', ('tail' 'end' 'mucro'), <structure
element>] if the must word mucro is absent from a sentence or
chunk, as in The end of the tail is rounded, but to retain it if
mucro is present. If a word like end, which is not a must
word, is absent from the sentence the hint would not automatically be discarded,
but would be evaluated for overall matching as previously discussed.
After all the nodes that have matched sufficiently well have been added
to the chunk's hierarchy the lowest level elements in the hierarchy become
possible candidates. A candidate may consist of a structure, one of its
properties, and a state, e.g., Body, posture, weak C. Some structures
and properties may match well, but it may happen that the system does not
find any state hint if the state used in the description is not currently
in the schema. For example, in a sentence such as The body posture is
a widely open C, if widely open C is not yet part of the schema
we would still want to maintain Body, posture as a candidate. Each
candidate is scored on how well it matches at each level in the node hierarchy
and these scores are combined to form an overall score. The candidates
are rank-ordered, first by simple heuristics, and then by their scores
within a given rank. For example, candidate characters having hints for
states or values are ranked above those that do not. If two states for
the same property are candidates, only the one with the highest score is
maintained in the list.
There are a few other elements in the system, such as Exact Hints
and Table Hints, which help in specific expected situations. For
example, measurements are often given in the form <character abbreviation>=
<measurement>, such as a = 12.4, which gives the value for
ratio a. If the same character appears in a table, the row header
might simply be the letter a. A special table hint would allow the
system to recognize this character.
Performance
In this section we examine the efficiency of the various activities
associated with the extraction of published data, from pre-processing the
printed text (i.e., scanning the document, optical character recognition
(OCR), and spell checking) through extracting the data (i.e., running the
Terminator), paying particular attention to how much time it takes to accomplish
each step, according to tests made in 1993. We did not try to conduct formal
replicated tests with different operators. In fact, the operator can take
many different courses of action with a highly interactive system like
the Terminator, and the time to carry out some actions is very much dependent
on a complex context that is difficult to characterize. For example, a
schema change may take only a few seconds when it requires only a simple
action (e.g., adding a state or a basic property to an existing structure)
or it may require a lengthy study of a complex situation by the domain
expert. Our goal in 1993 was to demonstrate proof of concept, that is,
that this is a practical tool for the job of building this type of database.
We tested the system on sixteen descriptions as part of an initial effort
to obtain data for approximately fifty species of plant-parasitic nematodes
of interest to the California Department of Food and Agriculture. The descriptions
were scanned and spell-checked by a student assistant and the Terminator
was used to process 16 description blocks, representing 12 text blocks
and 4 table blocks. The descriptions were not processed with the idea of
obtaining the fastest possible times, and they reflect the nematologist
(RF) working efficiently but carefully as time allowed over several weeks
to obtain error-free data.
On the average it took 12 minutes per page (with a range of 7 to 28 min/page)
to pre-process descriptions (16 min/page for data presented in tables)
prior to data extraction by the Terminator. The average description (text
block) was 1.3 pages long. This pre-processing time included scanning the
article, sometimes rescanning in case of a poor scan, running the OCR processing,
and spell checking using a word processor. It should be noted that the
time needed for OCR processing (using AccutextTM software) varied greatly
depending on whether a training function (the Verifier) was on or
off, with the verifier taking significantly more time than straight OCR
operations (i.e., after training is completed and the verifier is off).
Since we were processing from different journals, the verifier was often
on, which slowed the process. Descriptions that included data arranged
in tables took longer because of the need to reduce the various formats
used for printed tables into the single format that can be read by the
Terminator.
Data Extraction Times
Tables 1 and 2 give the times for data extraction from 16 descriptions
using the Terminator. Table 1 gives
the results for processing descriptions without any data tables (12 descriptions),
and Table 2 gives results for 4 data
tables processed separately. The processing time included the time the
Terminator takes to process the text as well as the interactive time the
operator takes to accept or input the data. The number of characters extracted
from the description and the number of schema changes were also recorded.
On average for the 16 descriptions, there were 64 characters per description
and approximately 3 characters were processed per minute. The average time
was 21.5 minutes per description. Processing the descriptions without data
tables (Table 1) took 26.3 minutes per description, with 2.80 characters
per minute and 74 characters per description. The schema had to be modified
4.9 times per textual description. This rather large number is probably
due to the fact that the tests were made at a time when the concepts of
schema building were not fully developed and the nematode schema used included
many missing characters and improperties. Changes would be far less extensive
with the current schema. The number of schema changes and the time for
processing the text was greater than for tables.
The pre-processing operator was paid $5.58/hr and the scientist extracting
the data was paid $25/hr, which means that it cost about $12.50 to completely
extract the data from one description. It would cost about $100,000 for
extracting the data from the 8,000 published descriptions of plant parasitic
nematodes, a sizable sum but well within funding possibilities of large
organizations.
Qualitative Performance
In addition to processing times, we also recorded the qualitative performance
of the Terminator by checking how well it found the correct characters
on its own (without the help of the operator) in one of the descriptions,
(i.e., Table 1, line 2) selected at random. Since the test involved running
the Terminator a second time on a description that had already been processed,
there were no characters missing from the schema. Therefore, this gives
a better indication of the Terminator's performance when the schema is
nearly complete (i.e., it includes all the characters that are present
in the description being processed). It should be noted that the Terminator
was tested at a time when we were still grappling with problems associated
with the decomposition and representation of traditional characters. Solutions
described in Diederich (1997) and Diederich et al. (1997a) will make it
much easier to build an initial and partially complete schema, even before
starting with description processing.
In this test, if the correct candidate character, i.e., correct structure,
property, and state/value, appeared in the display (among the first five
suggested candidates), we called this a perfect match. In such cases, the
operator only had to accept the character, possibly after selecting the
correct one from among the displayed list of five candidates. Since these
are very fast operations, we gave them the maximum score.
If the correct structure and/or property appeared in the first five characters
but had the wrong state or value, we called this an incomplete match. In
this case the operator had to select the candidate, get a path through
the schema hierarchy, select the correct state/value or input the correct
value, and accept the character from the hierarchical display. These are
fast operations too, but not as fast as accepting the correct character
directly from the initial pane.
Finally, in some cases, the state/value was missing because of our design
decision to display only one candidate among all those that have the same
property but different states and to print only the first measurement with
each candidate even when there are multiple measurements in a chunk. In
other cases, the data were missing because the Terminator takes a conservative
approach to numerical problems introduced by the scanner. For example,
the measurement I 8 (I7-2o) would not be corrected to 18 (17-20)
and recognized as an average and range. Instead the Terminator recognizes
the range and the number 8 as separate values and the operator needs to
enter the correct values in pane 6.
We called it a mismatch when the correct candidate was not among the first
five candidates. When this happens, the operator had to do a Find
on a selected word to get to the correct character. An alternative would
be to scroll through the list of other candidates. Choosing one method
over another is a question of personal preference. Doing a Find
and accepting from the path is approximately as fast as scrolling, while
scrolling is more demanding because it requires reading through the candidates.
The results of this test were as follows. For measurement characters, usually
simple and easier to recognize, the system achieved a perfect match 67%
of the time, an incomplete match 25% of the time, and a mismatch the remaining
8% of the time, to yield an overall score of 76%. Even with the more difficult
descriptive characters the Terminator did quite well, as the percentages
were 55, 31, and 14, respectively, for a score of 71% on the descriptive
characters only.
It should be noted that, even in those cases in which the Terminator did
not find the correct character on its own, the alternative actions described
above allowed the operator to process the data. In this sense, the overall
success rate for the tool together with its human operator was 100%.
Discussion
The Terminator offers a viable means of capturing and supplying data
from the published literature for use in populating general morphological
databases for any biological group. It may also be useful in other areas,
perhaps outside biology. This is an important advance, since other approaches
either would not work at all (e.g., when manual data extraction and entry
is not a practical option) or would require extensive effort with the resulting
costs possibly outweighing the benefits. As we indicated, natural language
processing in biological domains might require considerable independent
effort in each domain. Not only was the Terminator successfully used to
extract data in nematology, but it proved to be fast, easy, flexible, and
reliable. Much of this is due to its interface and related functionality.
The Terminator would also be particularly well suited to the concept of
an electronic journal as an on-line database. Electronic publication is
making progress, but the electronic journals we have seen implemented or
tested so far propose full-text materials, that is, materials in which
the data are not formatted and are embedded in extraneous material. This
makes queries difficult and many types of direct use virtually impossible.
A typical keyword search often returns unwanted elements resulting from
query string mismatches, which represents a down side of this approach.
Alternatively, an electronic journal could consist of one or several on-line
databases. Authors would use Terminator to represent their data in the
format of these general databases prior to adding the formatted data to
the general pool of descriptions.
The Terminator interface has been refined and tuned many times, not only
to make actions fast, but to make the layout and the nature of the actions
easy on the operator to perform tasks, considerably reducing the fatigue
factor. Easy usage relies first and foremost on both obvious and subtle
aspects of the interface that require a great deal of tuning. Though we
have not fully used the concept of Visual plan (Diederich &
Milton, 1993), which relies on the arrangement of the various panes in
the tool for suggesting the most likely course of action, it has influenced
our design. It has made how to use this complex tool relatively easy to
remember, even when one has not used it for a considerable time.
Easy usage helps with reliability too, since the operator can then be more
attentive to the data that is being entered. However, smooth operation
can actually be a problem in that it can lull the operator into a false
sense of security. Fortunately, warnings such as those we have implemented
for the change of type and stage will help overcome this potential problem.
A tool is also available that is used to review the results, review data
that has been tagged by one or more of the various indicators discussed
earlier, and show which chunks have not had any data accepted yet in a
description.
Another aspect of the tool is that it allows the operator ways to handle
unusual or difficult situations. Without such capabilities it might become
difficult to manage large sets of descriptions. Just keeping track of what
needs to be reexamined could be troublesome. For example, there may be
problems in deciding where to place a piece of data. In Globodera pallida
the live females are white, but after they die they become dark brown cysts
full of eggs. In the chunk Some populations pass through a four to six
week cream stage before turning brown, it is not clear whether the
cream color should be attributed to the female or to the cyst. The Terminator
solution to this type of problem is to rely on the flexibility built in
the schema and in the knowledge base that will be attached to it. In case
of ambiguous statements or characters, the operator chooses one of the
options (e.g., cyst, color) and explains the nature of the ambiguity in
a memo attached to the character. Later, appropriate relationships will
link the two characters so that an entry in one can be compared to an entry
in the other.
The Future Version of Terminator
As indicated above, the 1993 prototype is no longer available and funding
is being seeked to create a new version of the tool. The major changes
and principals we determined for designing the characters will necessitate
reformulating the design of the terminator from the top to the bottom.
For example, the prototype showed that even a relatively simple Terminator
could be used to do the job but it did not try to "learn" from
the data it had processed. The new one would.
Obviously, it is too early to indicate what this tool will be, how it will
operate, and what its interface will be. These points will be defined in
the design phase of the implementation of the tool, once it is funded.
At this moment, we can only indicate some avenues we will explore.
The interface : easier to use and more intuitive
We will try to implement fully the visual plan concept.
The data : uniform representation
We will integrate the new concepts defined since the time the prototype
was built: basic properties, structures, views. For example, the prototype
top 5-panel display will be replaced by a 3-panel display with structures-basic
properties-states/values.
Extraction and formatting engine : smarter
Operating principles will take advantage of the new concepts. For example,
the search of terms in the prototype put on the same footing all the terms
in the schema. As a consequence, the list of suggestions at times was quite
wrong. For example, if the text included "Tail round", the tool
would also propose "Spermatheca/shape, round", because of the
similarity in shape. The final version will give priority to structures
over basic properties and values.
Acknowledgements
This work was supported in part by grant of the California Department of Food and Agriculture, Exotic Pest Research N° 3498.
References
Anon. (1996). Communications of the ACM, Special Issue on Natural
Language Processing. Vol. 39, No.1, Jan. 1996.
Cowie,J. and Lehnert,W. (1996). Information extraction. Comm. ACM, 39, 80-91.
Diederich,J. (1997). Basic properties for biological databases: character development and support. Journal of Mathematical and Computer Modelling (in press).
Diederich,J., Fortuner,R. and Milton,J. (1997a). Construction and integration of large character sets for nematode morpho-anatomical data. Fundamental and Applied Nematology (in press).
Diederich,J., Fortuner,R. and Milton,J. (1997b). A general structure for biological databases. In: Bridge,P., Jeffries,P. Morse,D.R. and Scott,P.R.(eds)Information Technology, Plant Pathology and Biodiversity. CAB International, Wallingford, UK. (in press).
Diederich,J. and Milton,J. (1993). Expert workstations: a tool-based approach. In: Fortuner,R. (ed.)Advances in computer methods for systematic biology: artificial intelligence, databases, computer vision . The Johns Hopkins University Press, Baltimore, pp. 103-123.
Harris,Z., Gottfried,M., Ryckman,T., Mattick, Jr.,P, Daladier,A, Harris,T.N. and Harris,S. (1989). The form of information in science. Kluwer Academic Publishers, Dordrecht, The Netherlands.
Jacobs,PS. (1992). Text-based intelligent systems: current research and practice in information extraction and retrieval. Lawrence Erlbaum Associates, Hillsdale, N.J.
Salton,G. (1989). Automatic text processing : the transformation, analysis, and retrieval of information by computer. Addison-Wesley, Reading, Mass.
Samuelson,P. (1992). Copyright law and electronic compilation of data. Communications of the ACM , 35, 27-32.
Samuelson,P. (1996). Legal protection for database contents. Communications of the ACM, 39, 17-23.
{kind=link}
{kind=link}